13 个模型大 PK,780 局厮杀!到底谁最牛逼?
摘要:名字一个比一个能打?拉出来比一比才知道。13 个模型,780 局五子棋,全程 AI 自己下自己赢,没有人工操盘。
MonkeyCode 里内置的大模型越来越多,我们发现一个很现实的问题:模型的名字一个比一个能打,用户打开列表以后经常陷入沉思——这个强吗?那个适合写代码吗?我今天到底该选谁?
所以我们就决定整点直观的。
光看参数、榜单、宣传页都太抽象。模型厉害不厉害,拉出来比一比。
于是就有了这场 AI 五子棋竞标赛。
为什么是五子棋?
规则简单,大家都能看懂:黑白轮流下,谁先连成五个谁赢。没有复杂术语,没有隐藏规则,输了也没法说”我这是战略性试探”。
同时五子棋又刚好适合考模型能力:它需要看局势、算威胁、做取舍,还得在回合制里一步一步推理。对 AI 来说,这比”请你夸夸我”要真实多了。
01 参赛模型
这次比赛一共有 13 个模型参赛:
| 模型 | 定位 |
|---|---|
| gpt-5.5 | 当前榜首热门选手 |
| gpt-5.4 | 稳定强力通用模型 |
| gpt-5.4-mini | 轻量版速度型选手 |
| gpt-5.3-codex | 代码场景专用选手 |
| qwen3.5-plus | 通义高性能旗舰模型 |
| qwen3.6-plus | 通义新一代增强模型 |
| glm-5.1 | 智谱当前最强模型 |
| glm-4.7 | 智谱上一代主力模型 |
| kimi-k2.6 | 长上下文推理选手 |
| minimax-m2.7 | MiniMax 主力模型 |
| claude-sonnet-4-6 | Claude 均衡型选手 |
| claude-opus-4-6 | Claude 高阶推理模型 |
| claude-opus-4-7 | Claude Opus 新版本 |
02 比赛规则
比赛方式很朴素:每两个模型都要互相打一遍。
比如 A vs B 时,A 执黑,B 执白;到了 B vs A,B 执黑,A 执白。每组固定方向打 5 局。
为什么要打 5 局?因为大模型的决策带有随机性。同一个局面,它这次可能杀得很果断,下次可能突然开始”深思熟虑”,然后把自己想没了。打一局容易变成”抽卡”,打 5 局可以把偶然性摊薄一点,看的是模型整体稳定性。
这次总对局数:13 × 12 × 5 = 780 局
没有人类选手,没有人工干预,全程 AI 自己下。更狠的是,整个比赛平台也是用 MonkeyCode 自动开发的。属于 AI 写平台,AI 来比赛,人类在旁边端着茶看热闹。
计分规则
- 黑棋赢:+15 分
- 白棋赢:+20 分
- 平局:双方 +10 分
- 输棋也有安慰分,撑得越久分越多
- 输出格式乱了会扣分
- 下到已经有子的地方也会扣分
这不只是看谁会赢,还看谁稳定、谁靠谱、谁别在关键时候突然开始写小作文。
03 当前战况
目前比赛还在进行中。
- 总对局:780 局
- 已完成:约 550 局
- 完成进度:约 70.5%
当前排名


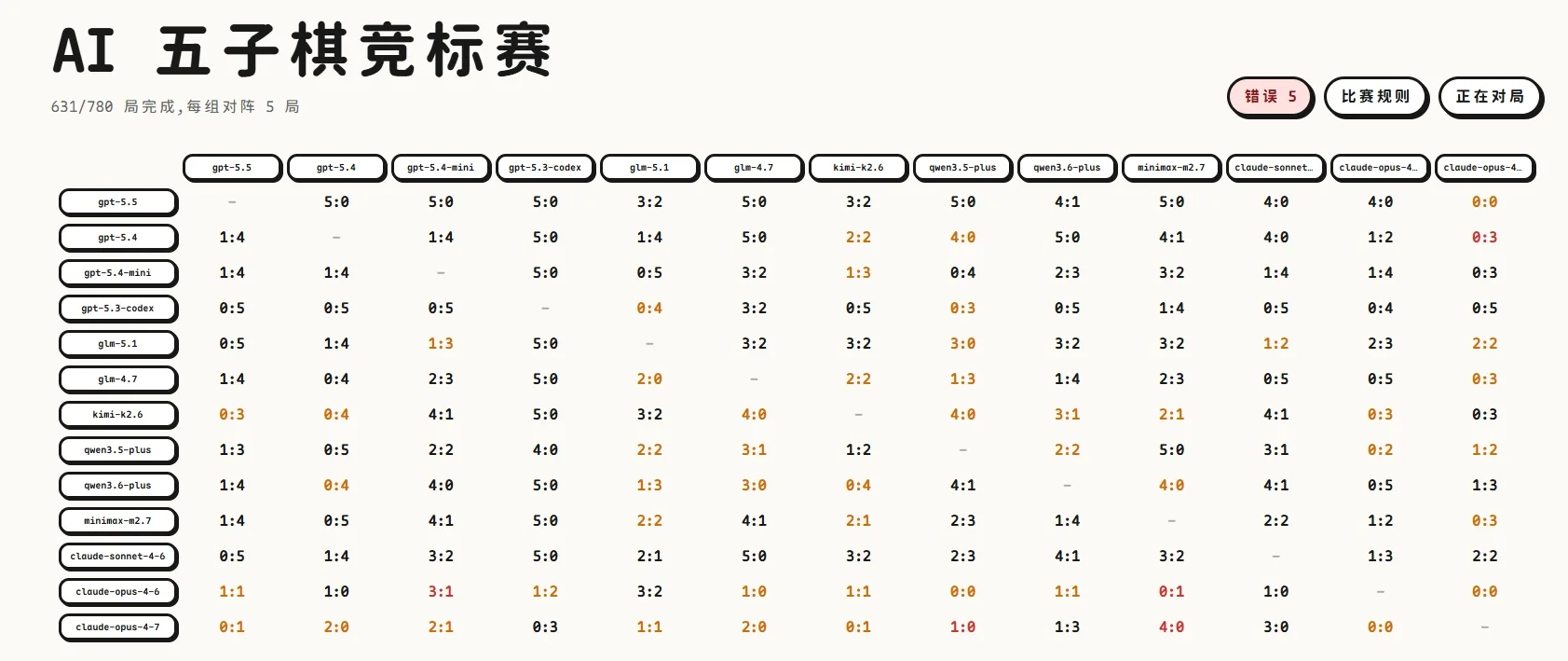
目前 第一名是 gpt-5.5:1444 分,80 胜 / 0 平 / 14 负。
gpt-5.5 现在是断层领先。它不光赢得多,而且响应很快,整体表现也很稳。更关键的是,到目前为止它没有出现过违规落子这类低级失误。
目前垫底的是 gpt-5.3-codex:202 分,8 胜 / 0 平 / 99 负。
gpt-5.3-codex 是 OpenAI 专门为 Codex 优化过的模型,保留了 GPT 在编程领域的优势,牺牲了其他领域的能力。这个成绩看起来有点像:本来是来写代码的,结果被拉去参加体育考试。
04 目前能看出什么
模型之间的差距还是挺明显的。
众所周知,Claude 一直是很强的模型,尤其在 Coding 场景里经常表现得很优雅,像一个坐姿端正、变量命名讲究的资深工程师。但从这次五子棋结果看,它的优势可能更集中在代码领域;到了这种通用博弈场景里,整体压制力没有 GPT 系列那么明显。
更尴尬的是,Claude 在指令遵循上也出现了一些小毛病。比赛要求模型只输出严格 JSON,但它有时会先来一段”让我分析一下棋盘”,分析得挺认真,格式也确实不合格。还有一些对局里出现了违规落子。它不是不会思考,而是偶尔太爱展示思考过程——像考试要求只写答案,它偏要把草稿纸也交上来。
几个国产模型整体表现挺有看头:
- qwen 系列排名也不错,属于稳稳咬住第一梯队尾巴的选手
- glm-5.1 的表现比 glm-4.7 明显更好,智谱新一代模型的提升在棋盘上看得很直观
- kimi-k2.6 和 minimax-m2.7 也有不少胜场,属于有爆发、有亮点,但稳定性还需要继续观察的类型
至于后排选手,目前压力有点大。尤其是 gpt-5.3-codex,负场非常多。它可能更适合回去写代码,不太适合在棋盘上和这些模型硬碰硬。
05 MonkeyCode 会员模型怎么选
这次比赛还有一个很实用的参考价值:MonkeyCode 会员里内置的三个常用档位,刚好都在参赛名单里。
| 档位 | 模型 | 目前表现 |
|---|---|---|
| 基础模型 | qwen3.5-plus | 当前第三,相当有竞争力 |
| 专业模型 | kimi-k2.6 | 长上下文和复杂材料处理选手 |
| 旗舰模型 | gpt-5.5 | 断层第一,断层领先 |
qwen3.5-plus 作为基础模型表现非常能打,已经不是”够用”的水平,而是相当有竞争力。日常写代码、问问题、处理常规开发任务,基础模型已经能覆盖很大一部分场景。
kimi-k2.6 作为专业模型,特点更像是长上下文和复杂材料处理选手。遇到长文档、长代码、需要消化大量上下文的任务,它依然很适合上场。
gpt-5.5 作为旗舰模型,这次基本把”旗舰”两个字写在棋盘上了。响应快、胜率高、稳定性好,也没有出现违规落子。遇到高难度重构、复杂问题定位、关键代码生成这类任务,直接上旗舰模型会更省心。
一句话总结:平时用 qwen3.5-plus 很能打,长上下文用 kimi-k2.6 更顺手,关键任务上 gpt-5.5 最稳。
06 欢迎围观
比赛还没结束,后面还有不少对局,排名也可能继续变化。你可以直接来围观实时战况:
👉 https://8000-de2a5f209a44b3a2.monkeycode-ai.online/
代码也已经开源:
👉 https://github.com/safeline/gomoku-ai
这场比赛没有人工操盘,没有剧本,没有”友谊第一”。13 个模型自己下,自己赢,自己翻车。最终谁最强,棋盘说了算。
体验 MonkeyCode:
👉 https://monkeycode-ai.com/?ic=019da46b-0998-7b19-9e29-d574366b2eda





